sudo journalctl -u earlyoom | grep sending
可以快速定位日志记录位置
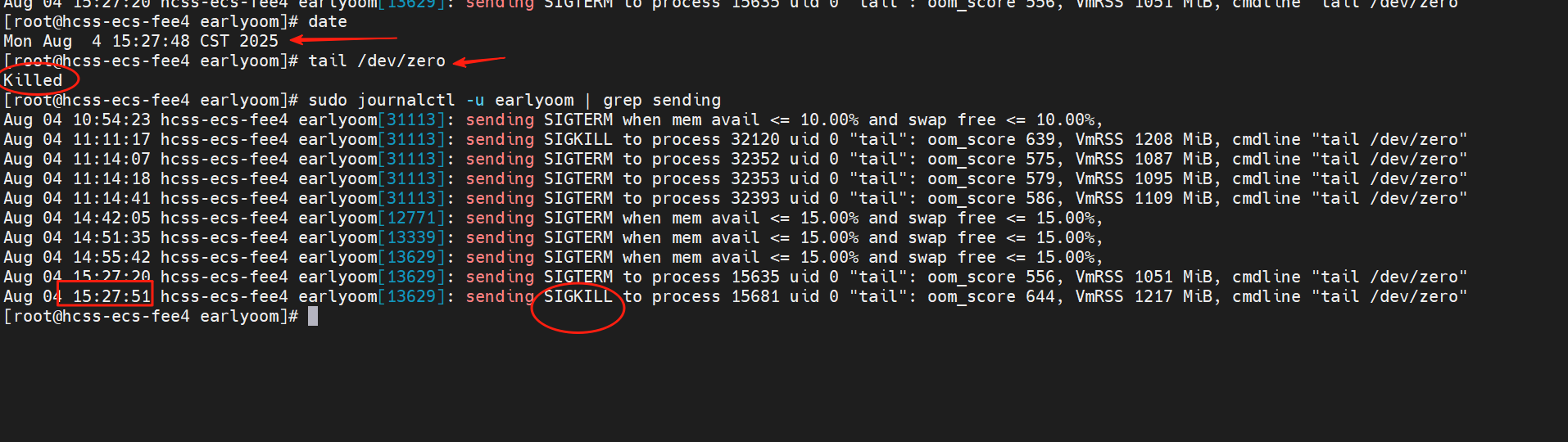
如果频繁OOM,优先建议升级内存来解决内存不足的问题。
针对偶发内存不足,避免服务器卡死,安装earlyoom是一个非常不错的解决方案。内核内的 oom-killer无法配置为早点介入, Linux 仅在绝对没有其他选择时才调用它,服务器会出现卡死,导致SSH无法登录,VNC远程黑屏、业务掉线等情况,每次重启或断电重启后才能恢复正常。
具体部署与否根据业务判断,这里简单介绍一下部署earlyoom的流程,github开源项目
https://github.com/rfjakob/earlyoom
安装部署(这里以centos系统举例):
yum install -y git systemctl stop firewalld git clone https://github.com/rfjakob/earlyoom.git #克隆github仓库 cd earlyoom/ make sudo make install #systemd,将其注册为系统服务earlyoom sudo make install-initscript # non-systemd #然后直接启动刚刚编译的可执行文件 ./earlyoom
这里就会显示内存以及交换分区的使用情况,我这里使用的是云服务器,没有交换分区。可以看到SIGTERM和SIGKILL两个信号,这里可以联想一下我们平时用的kill和kill -9这两个命令,大致意思就是如果 内存和交换分区的available值同时满足小于等于10%,那么就会触发这个SIGTERM信号,即kill,然后小于等于 5%即为 kill -9 强制结束进程。当然这个是默认的配置,还可以根据需要进行调整的,详情可以看常用参数。
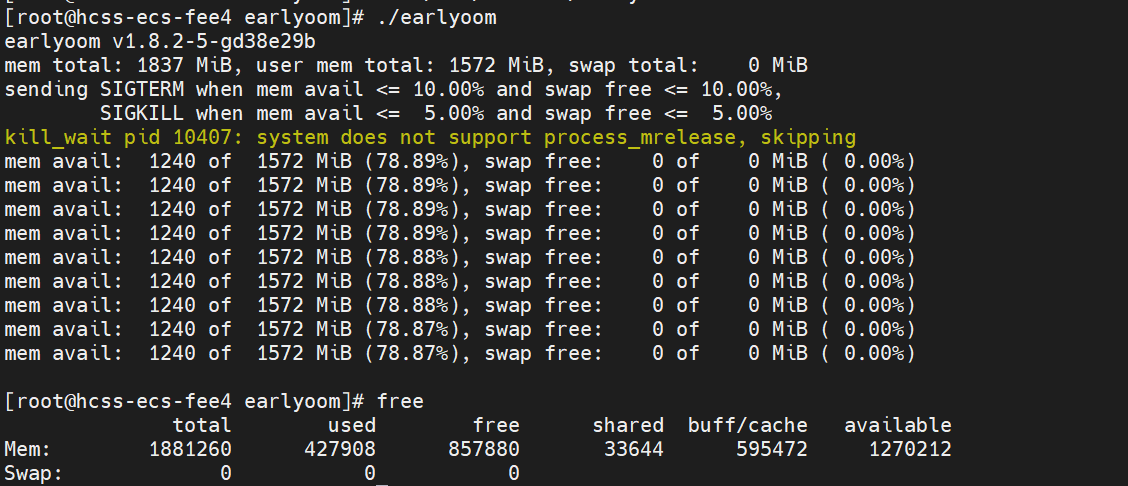
常用参数(这个后续可以用在配置文件里面修改实现永久有效)
[root@hcss-ecs-fee4 earlyoom]# ./earlyoom --help
-m PERCENT[,KILL_PERCENT] 设置可用内存最小百分比 (默认 10%)。
低于此值发送 SIGTERM 信号,低于 KILL_PERCENT 时发送 SIGKILL 信号 (默认 PERCENT/2)。
-s PERCENT[,KILL_PERCENT] 设置可用交换空间最小百分比 (默认 10%)。
-M SIZE[,KILL_SIZE] 设置可用内存最小值 (以 KiB 计)。
-S SIZE[,KILL_SIZE] 设置可用交换空间最小值 (以 KiB 计)。
-n 启用 d-bus 通知。
-N /PATH/TO/SCRIPT 进程被杀死后执行脚本。
-g 杀死整个进程组。
-d, --debug 启用调试信息。
-v 显示版本信息并退出。
-r INTERVAL 内存报告间隔(以秒计,默认 1),设为 0 可禁用。
-p 设置 EarlyOOM 的 niceness 为 -20 和 oom_score_adj 为 -100。
--ignore-root-user 不杀死 root 用户的进程。
--sort-by-rss 按 RSS 大小选择进程而非 oom_score。
--prefer REGEX 优先杀死符合正则表达式的进程。
--avoid REGEX 避免杀死符合正则表达式的进程。
--ignore REGEX 忽略符合正则表达式的进程。
--dryrun 干跑模式(不杀死任何进程)。
--syslog 使用 syslog 记录日志。
-h, --help 显示帮助信息。
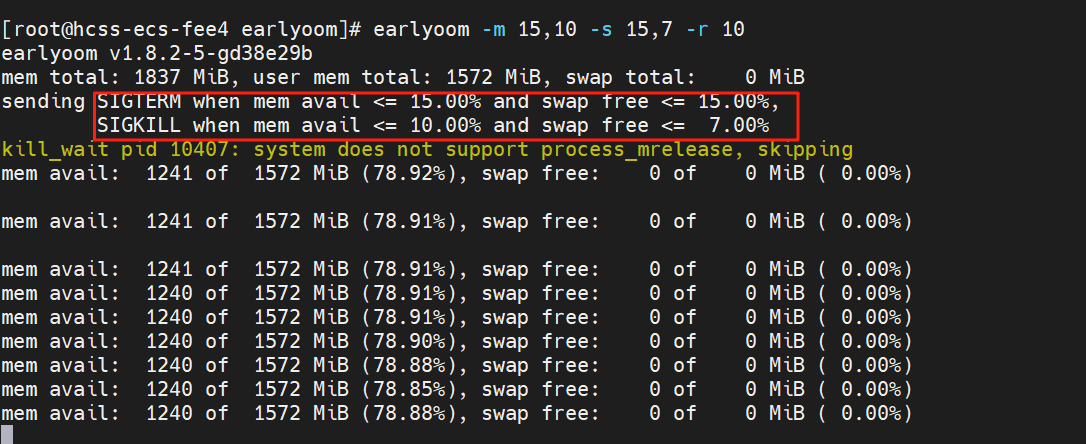
#例如我这里自定义内存阈值和wap阈值的百分比,并且间隔为10s,-m 15,10 -s 15,7 -r 10
那么命令就是
earlyoom -m 15,10 -s 15,7 -r 10
配置文件
上述提到了在shell界面输入 earlyoom -m 15,10 -s 15,7 -r 10 实现临时生效,这个关闭终端或者结束进程后,还是会使用默认的配置,并且手动的earlyoom不会读取配置文件/etc/default/earlyoom里面EARLYOOM_ARGS=”-m xx -s xx” 内容。
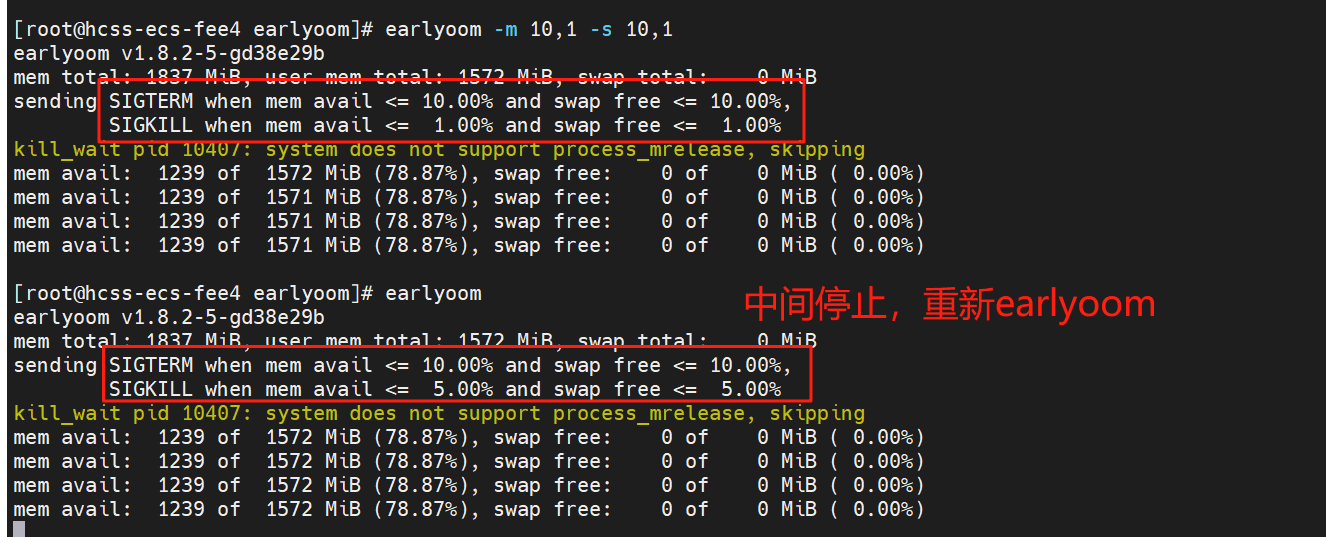
如果要实现长期、持久化的配置,一般是需要写入配置文件形成“策略”才行。
/etc/default/earlyoom #配置文件修改后需要重启服务
在文件里面设置,EARLYOOM_ARGS=”-m xx -s xx” ,然后后续重启earlyoom服务。
默认配置:
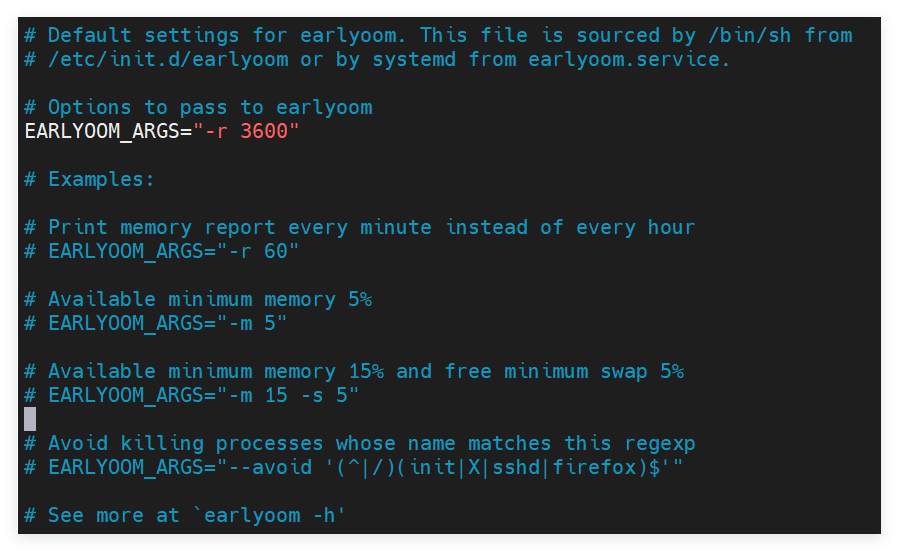
这里设置阈值,-m 15,7 -s 15,7
命令
vim /etc/default/earlyoom EARLYOOM_ARGS="-m 15,7 -s 15,7 -r 1" systemctl restart earllyoom
查询进程

这个时候就不能像之前那样直接输入earlyoom看实时信息了,再去输入的话又是10,5的默认配置,这两个属于不同的场景了,可以理解为一个是用户层面,一个是系统层面。
这里可以使用 journalctl 查看,我们平时看system 服务报错的时候,也会提示 journalctl 去查看日志。
journalctl -u earlyoom
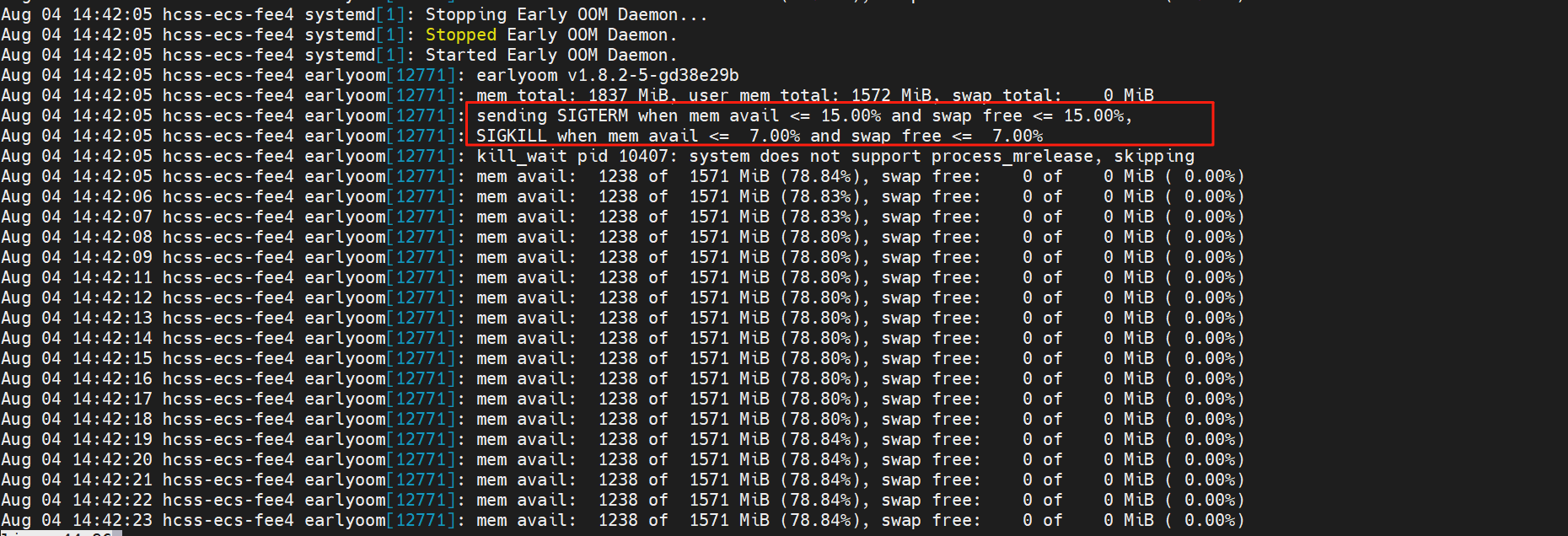
实时跟进的话,journalctl 还需要添加一个 -f 实现
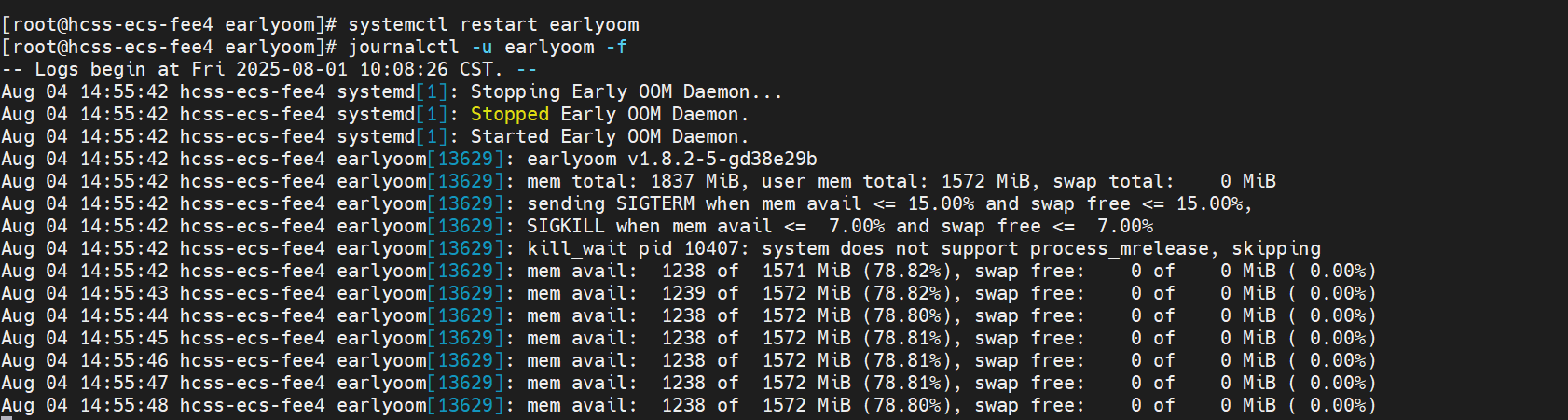
当然,如果真的达到阈值条件触发了kill,我们就可以通过journalctl捕捉到这条信息,这里使用
附:
journalctl常用参数
-u <服务名>:仅查看指定系统服务的日志(最常用)。
示例:journalctl -u earlyoom(查看 earlyoom 服务的所有日志)。
-t <标识符>:按日志的 “标识符” 筛选(如程序名)。
示例:journalctl -t sshd(查看 sshd 相关日志)。
-f:实时跟踪日志更新(类似 tail -f),适合监控正在发生的事件。
示例:journalctl -u nginx -f(实时查看 nginx 日志)。
–no-pager:直接输出全部日志,不分页(方便管道处理)。
示例:journalctl -u ssh –no-pager | grep “Failed”(筛选 ssh 登录失败记录)。
–since <时间>:查看某个时间点之后的日志。
支持格式:具体时间(2025-08-04 10:30)、相对时间(1h ago 1 小时前、yesterday 昨天)。
示例:journalctl –since “1h ago”(近 1 小时的日志)。
–until <时间>:查看某个时间点之前的日志。
示例:journalctl -u earlyoom –since yesterday –until now(昨天到现在的 earlyoom 日志)。
-n <行数>:仅显示最近 N 行日志。
示例:journalctl -n 50(最近 50 行日志)、journalctl -u mysql -n 20(mysql 最近 20 行)。
-p <级别>:按日志级别筛选(级别从高到低:emerg > alert > crit > err > warn > info > debug)。
示例:journalctl -p err(仅显示错误级别日志)、journalctl -u apache2 -p warn(apache2 的警告及更高级别日志)。

