
一.整体类
top命令
top的一些用法:
排序类:
top命令默认是按照%cpu降序排列的,可以通过输入一些命令修改
提醒:都是大写字母!!!
P(大写):按 %CPU 降序排序(默认)——快速定位 CPU 占用最高的进程;
M(大写):按 %MEM 降序排序——快速定位内存占用最高的进程;
N(大写):按 PID 升序排序——按进程 ID 顺序查看;
T(大写):按 TIME+(累计 CPU 时间)降序排序——定位长期占用 CPU 的进程;
R(大写):反向排序(如当前是 CPU 降序,按 R 后变为升序)。
筛选类:
u:按照用户筛选,界面只显示该用户的进程
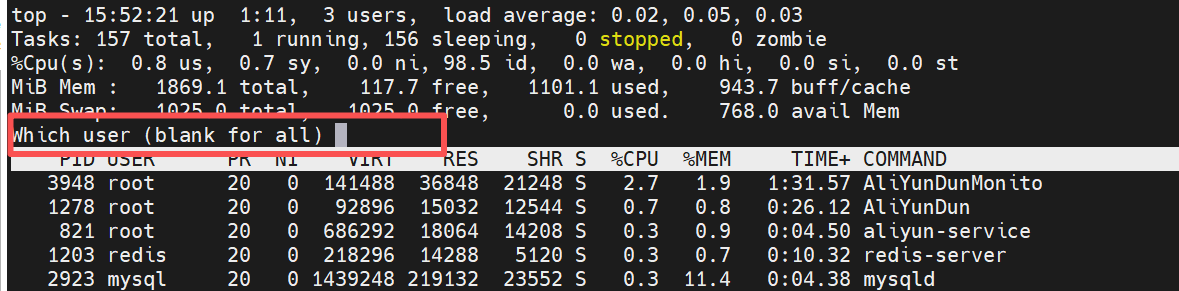
输入root,dba等等,界面只会显示该用户的进程
k :kill杀进程用,后面需要接进程的PID值,默认情况下是发送信号15(SIGTERM)的kill,即常规kill,这里补充一下kill,比如说系统中毒了,有病毒在吞资源,但是我们就算kill -9 强制删除进程后,如果进程隔一会又运行了,这个情况下,我们需要做的是 kill -STOP 这个命令来让这个进程停止运行,并保持进程存在,这样可以暂时的规避掉该进程消耗的计算资源,暂时恢复环境,后续再去排查可疑文件、病毒定时任务等内容。
/ :搜索进程名,比如/后搜索nginx,界面就会高亮显示匹配的进程,按n切换到下一个匹配结果,其实和我们vim编辑一个文件有点类似,查找,但是可能会提示未知命令,这个查找进程建议还是用ps去查找
界面类:
s(小写):刷新时间间隔,默认是3秒,比如输入s后写1,就是吧刷新间隔改为1秒
q :退出top进程
1 :切换cpu核心显示,展开多核下的单独使用情况
W(大写):保存当前配置,下次打开top就会使用当前的刷新规则,排序规则,筛选等等,文件保存到~/.toprc


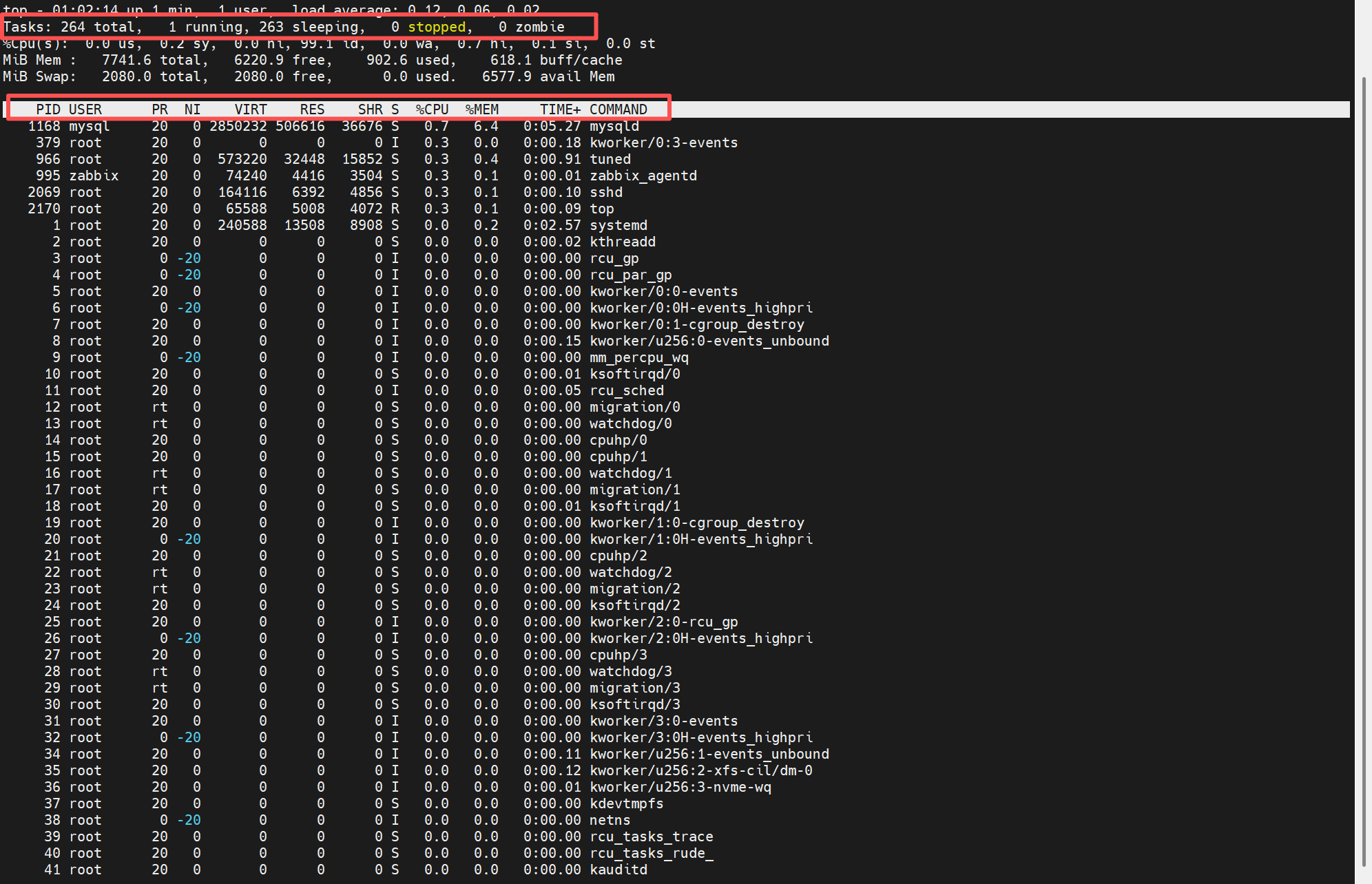
上图第一个红框标注行为进程和CPU信息,具体含义如下:
① Tasks: 进程的总数。 ② running:正在运行的进程数。 ③ sleeping:处于休眠的进程数。 ④ 0 stopped:停止的进程数。 ⑤ 0 zombie:僵死的进程数。 ⑥ Cpu(s): 0.0% us:表示用户进程占用CPU的百分比。 ⑦ 0.2% sy:系统进程占用CPU的百分比。 ⑧ 0.0% ni:用户进程空间内改变过优先级的进程占用CPU百分比。 ⑨ 99.1% id:空闲CPU占用的百分比。 ⑩ 0.0% wa:等待输入输出的进程占用CPU的百分比。 上图第二个红框显示了进程信息区每个进程的运行状态,每列输出的含义如下: ① PID:进程的id。 ② USER:进程所有者的用户名。 ③ PR:进程优先级。 ④ NI:nice值。负值表示高优先级,正值表示低优先级。 ⑤ VIRT:进程使用的虚拟内存总量,单位kB。VIRT=SWAP+RES。 ⑥ RES:进程使用的、未被换出的物理内存大小,单位kB。RES=CODE+DATA。 ⑦ SHR:共享内存大小,单位kB。 ⑧ S:进程状态,D表示不可中断的睡眠状态,R表示运行状态,S表示睡眠状态,T表示跟踪/停止,Z表示僵死进程。 ⑨ %CPU:上次更新到现在的CPU时间占用百分比。 ⑩ %MEM:进程占用的物理内存百分比。 ⑪ TIME+:进程使用的CPU时间总计,单位为1/100秒。 ⑫ COMMAND:正在运行进程的命令名或者命令路径。
vmstat命令
vmstat是Virtual Meomory Statistics(虚拟内存统计)的缩写,很多linux发行版本都默认安装了此命令工具,
利用vmstat命令可以对操作系统的CPU活动、内存信息、进程状态进行监视,不足之处是无法对某个进程进行深
入分析。
vmstat 2 5
每两秒执行一次采集,总计5次
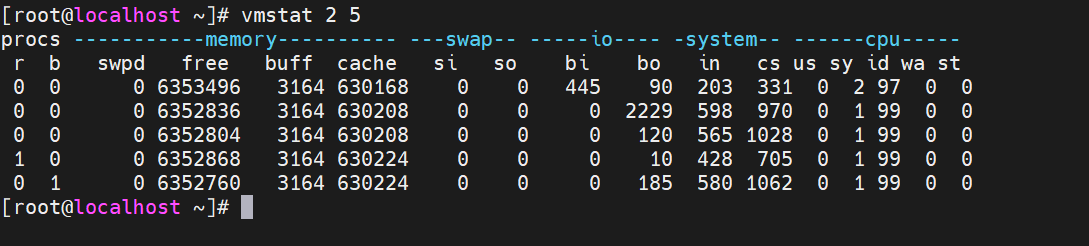
procs ① r列表示运行和等待cpu时间片的进程数,这个值如果长期大于系统CPU的个数,说明CPU不足,需要增加CPU。 ② b列表示在等待资源的进程数,比如正在等待I/O、或者内存交换等。 memory ① swpd列表示切换到内存交换区的内存数量(以k为单位)。如果swpd的值不为0,或者比较大,只要si、so的值 长期为0,这种情况下一般不用担心,不会影响系统性能。 ② free列表示当前空闲的物理内存数量(以k为单位) ③ buff列表示buffers cache的内存数量,一般对块设备的读写才需要缓冲。 ④ cache列表示page cached的内存数量,一般作为文件系统cached,频繁访问的文件都会被cached,如果cache值较大,说明cached的文件数较多,如果此时IO中bi比较小,说明文件系统效率比较好。 swap ① si列表示由磁盘调入内存,也就是内存进入内存交换区的数量。 ② so列表示由内存调入磁盘,也就是内存交换区进入内存的数量。 一般情况下,si、so的值都为0,如果si、so的值长期不为0,则表示系统内存不足。需要增加系统内存。 IO项显示磁盘读写状况 ① bi列表示从块设备读入数据的总量(即读磁盘)(每秒kb)。 ② bo列表示写入到块设备的数据总量(即写磁盘)(每秒kb) 这里我们设置的bi+bo参考值为1000,如果超过1000,而且wa值较大,则表示系统磁盘IO有问题,应该考虑提高 磁盘的读写性能。 system 显示采集间隔内发生的中断数 ① in列表示在某一时间间隔中观测到的每秒设备中断数。 ② cs列表示每秒产生的上下文切换次数。 上面这2个值越大,会看到由内核消耗的CPU时间会越多。 CPU项显示了CPU的使用状态,此列是我们关注的重点。 ① us列显示了用户进程消耗的CPU 时间百分比。us的值比较高时,说明用户进程消耗的cpu时间多,但是如果长期大于50%, 就需要考虑优化程序或算法。 ② sy列显示了内核进程消耗的CPU时间百分比。Sy的值较高时,说明内核消耗的CPU资源很多。 ③ id 列显示了CPU处在空闲状态的时间百分比。 ④ wa列显示了IO等待所占用的CPU时间百分比。wa值越高,说明IO等待越严重。 根据经验,us+sy的参考值为80%,如果us+sy大于 80%说明可能存在CPU资源不足。wa的参考值为20%,如果wa超过20%, 说明IO等待严重,引起IO等待的原因可能是磁盘大量随机读写造成的,也可能是磁盘或者磁盘控制器的带宽瓶颈造成的(主要 是块操作)。
二.CPU类
cpu的查看除了整体top,vmstat能看之外,还有一些常用于看CPU的命令,比如sar,mpstat,这个都算是sysstat工具集里面的内容。
如果没有sysstat可以先安装
yum install -y sysstat
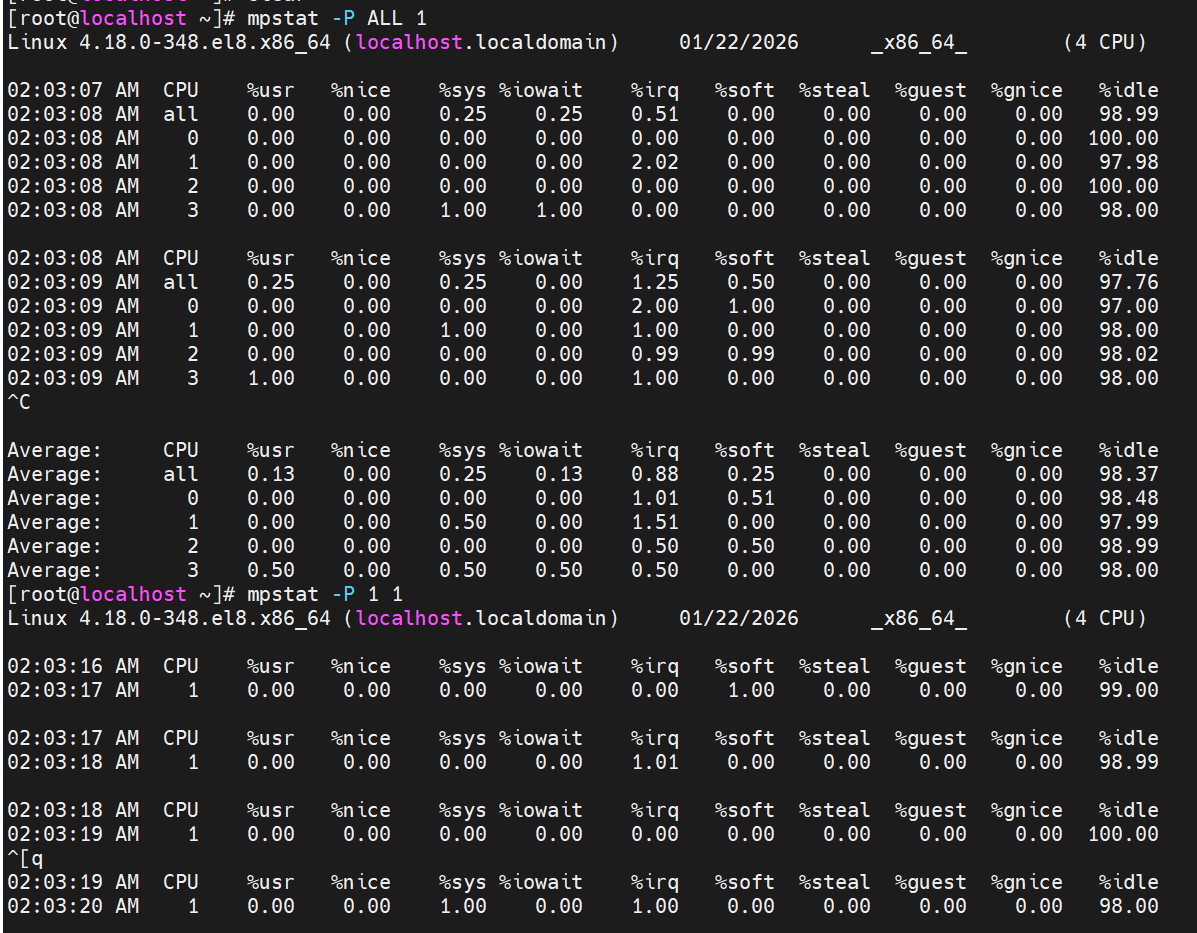
mpstat命令:用法和vmstat类似,但是区别在于,mpstat可以具体到某个CPU的情况查看,在top命令中按“1”也可以实现看多核状态。
mostat -P ALL :查看所有CPU的情况
mpstat -P 1:查看第二个cpu的情况
sysstat工具集下的sar命令 但是sar这个命令不是局限于看CPU的,但是如果不加任何参数,它是查询的cpu信息 例如 sar 2 5 #采集五次数据,每两秒执行一次 它其实等同于 sar -u 附: sar按资源查看 ● sar -u:CPU 使用率(默认)。 ● sar -r:内存使用情况。 ● sar -b:I/O 传输速率。 ● sar -n DEV:网络设备统计。 ● sar -q:系统负载和队列长度。 当然,除了手动输入命令采集,启动sysstat服务后,里面有一个叫 sadc的东西(System Activity Data Collector),数据收集器 它是sysstat非常重要的一环,可以将从内核中收集原始的性能数据,并将其格式化后写入到二进制文件中。
查询系统systemd定时器

工作模式
sysstat-collect.timer (每10分钟)
↓
sa1
↓
sadc
↓
/var/log/sa/saDD ← 二进制
sysstat-summary.timer (每天一次)
↓
sa2
↓
sar -A
↓
/var/log/sysstat/sysstat-YYYYMMDD ← 文本
原始采集数据 saxxx /var/log/sa/saxx 这个是二进制文件,需要sar来读,sar -f /path/to/confile
汇总日报 sarxx /var/log/sysstat/sar13 这个其实就是文本文件了,可以直接用cat/less来读就可以了。
但是我这里云服务器,它生成的sa文件和sar文件全在/var/log/sysstat里面。
三.磁盘IO
磁盘I/O一般就直接用iostat来看即可
iostat -x

里面会记录读写等性能参数,一般需要关注一下%util这个参数,不宜过高
%util在统计周期内,磁盘“至少有一个 IO 在处理”的时间占比
附:持续更新中
© 版权声明
文章版权归作者所有,未经允许请勿转载。



哇,学到了啊
6