
tc介绍
在日常的 Linux 节点运维与底层网络架构管理中,面对复杂的流量竞争,我们经常需要对特定业务进行精准的带宽限制与保障。Linux 内核网络协议栈自带了一把流量整形的“尖刀”——TC (Traffic Control)。
TC 是 Linux 内核中负责网络流量控制的模块。默认情况下,网络接口的发包策略是 FIFO(先进先出),尽最大努力传输。但通过 TC,我们可以对网卡的**出站流量(Egress)**进行排队、整形、丢弃等干预,从而实现 QoS(服务质量)保障。
tc一般是有三个核心组件,Qdisc(排队规则)、Class(类别)、Filter(过滤)
但是需要注意的是,不是所有的排队规则qdisc都会有这三个东西,比如只有qdisc的,咱们一般叫它无分类排队规则 (Classless Qdiscs),它的结构就比较简单,没有class(类别),也不需要filter(过滤器)。所有经过网卡的包一视同仁地排队。
比较常见的有
• fq_codel / cake:用来解决队列拥塞、降低游戏延迟的“神仙算法”。 • sfq (随机公平队列):尽量让每个连接公平传输。 • tbf (令牌桶过滤器):用来做最简单的整体限速(不能借用带宽,只能卡死一个上限),运营商可能就是通过令牌桶来进行板卡限速的,卡pcdn用户。 • pfifo_fast:Linux 默认的先进先出队列。
咱们网卡默认的可能就是fq_codel
第二种就是有分类规则的(Classful Qdiscs)
这就是包含 qdisc(根节点)、class(子类抽屉)和 filter(分拣员)的复杂体系。不仅仅是 HTB,只要是需要精细化分组的算法,都在这个阵营。
• 特点: 呈现树状结构。你可以无限嵌套(比如在 1000M 的根类下建 2 个 500M 的子类,在其中一个 500M 的子类下再建 2 个 250M 的孙子类)。必须依靠 filter 才能把数据包正确引导到对应的叶子节点。
但是现在filter似乎都不怎么用了,如果确实要过滤,可以结果iptables等打标机,来结合使用,一般都不会自己去写tc filter过滤,好像很晦涩,语法也不太人性。
常见代表: • htb(分层令牌桶):目前最主流、最容易理解的带宽分配算法。 • hfsc(分层公平服务曲线):** 比 HTB 更高级但也极其复杂的算法,OpenWrt 的高级 QoS 插件(如 SQM)底层有时会用它,能同时保证带宽和极低的实时延迟。 • prio (严格优先级):** 不限速,只给流量排个先后优先级(VIP通道优先走,平民通道等VIP走完了再走)。 • cbq: HTB 的老前辈,因为配置太反人类,现在基本被淘汰了。
htb测试
这里以HTB算法测试展开,简单了解一下tc限速的原理。
大致思路是,netns设置虚拟网卡做好网络拓扑+tc流量整形+iperf3打流测试
netns创建虚拟网卡
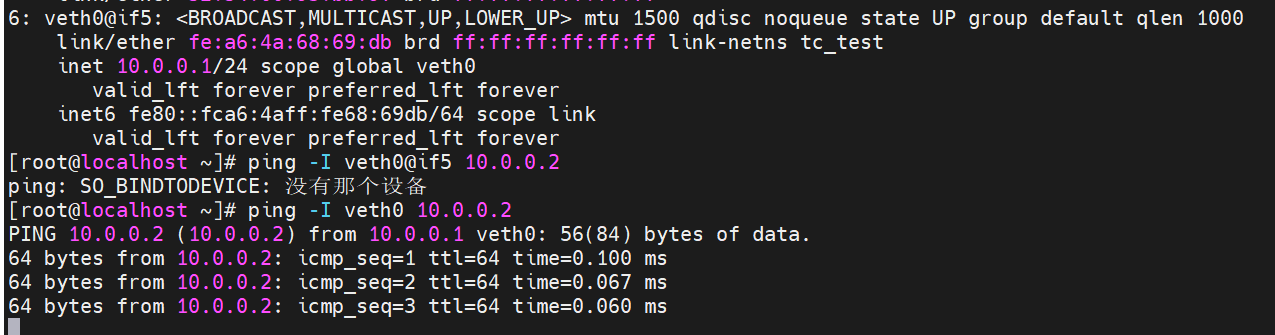
使用netns(network namespace)模拟 一对veth虚拟网卡设备,veth1当宿主机的网卡,veth2当tc_test里面的 # 1. 创建名为 tc_test 的 network namespace ip netns add tc_test # 2. 创建一对 veth 虚拟网卡设备 (veth0 和 veth1) ip link add veth0 type veth peer name veth1 # 3. 将 veth1 移入我们刚才创建的 ns_test 命名空间中 ip link set veth1 netns tc_test # 4. 为 Root Namespace 中的 veth0 配置 IP 并启动 ip addr add 10.0.0.1/24 dev veth0 ip link set veth0 up # 5. 为 tc_test 中的 veth1 配置 IP 并启动 ip netns exec tc_test ip addr add 10.0.0.2/24 dev veth1 ip netns exec tc_test ip link set veth1 up
流量整形
tc流量整形
#在tc_test的veth1 上配qdisc #根队列 ip netns exec tc_test tc qdisc add dev veth1 root handle 10: htb default 10 #子类class,rate保证带宽,ceil闲时触发最大带宽。一般会设置一个父类,多个子类。 ip netns exec tc_test tc class add dev veth1 parent 10: classid 10:1 htb rate 5mbit ceil 5mbit ip netns exec tc_test tc class add dev veth1 parent 10:1 classid 10:10 htb rate 1mbit ceil 2mbit ip netns exec tc_test tc qdisc show dev veth1 ip netns exec tc_test tc class show dev veth1

iperf3打流测试
iperf3打流
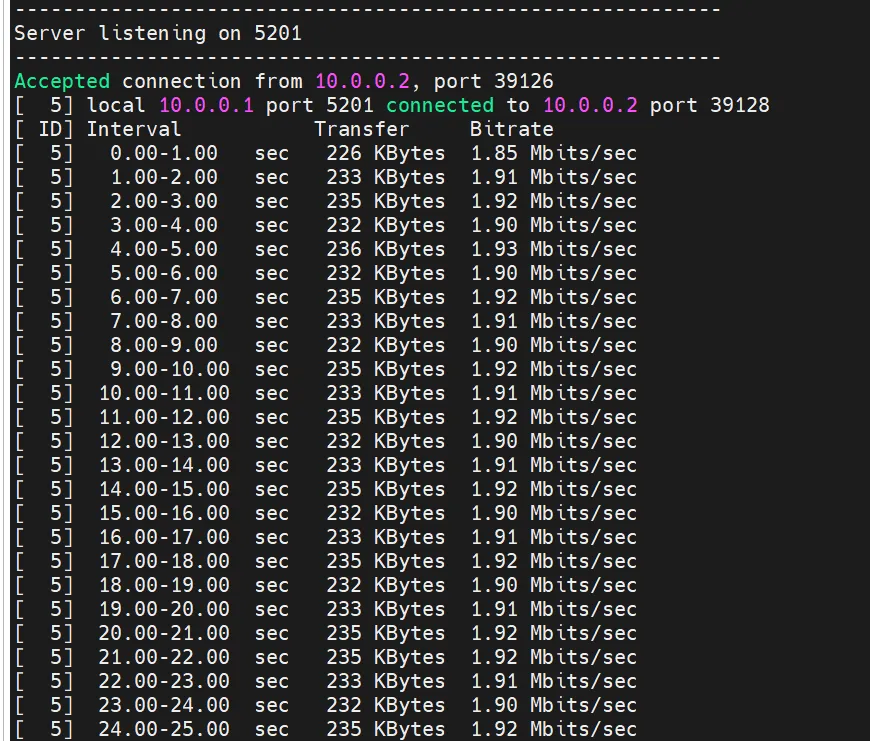
#服务端,默认监听5201 iperf -s #namespace内的veth2当客户端,打veth1 ip netns exec tc_test iperf3 -c 10.0.0.1 -t 100 -i 1
添加时间的限速
带宽一般是搭配时间段来进行限制的,或者进行全天的限速。这里介绍一种的办法进行限速,即通过定时任务的办法进行change,tc qdisc的时候有一个参数default 10,即在class类里面parent 10:1 classid 10:10的规则,通过定时任务,定期修改这个规则实现动态调整,而不是删除/添加.
这里模拟,每天0点开始限速,18点解除限速的定时任务来展开
crontab -e
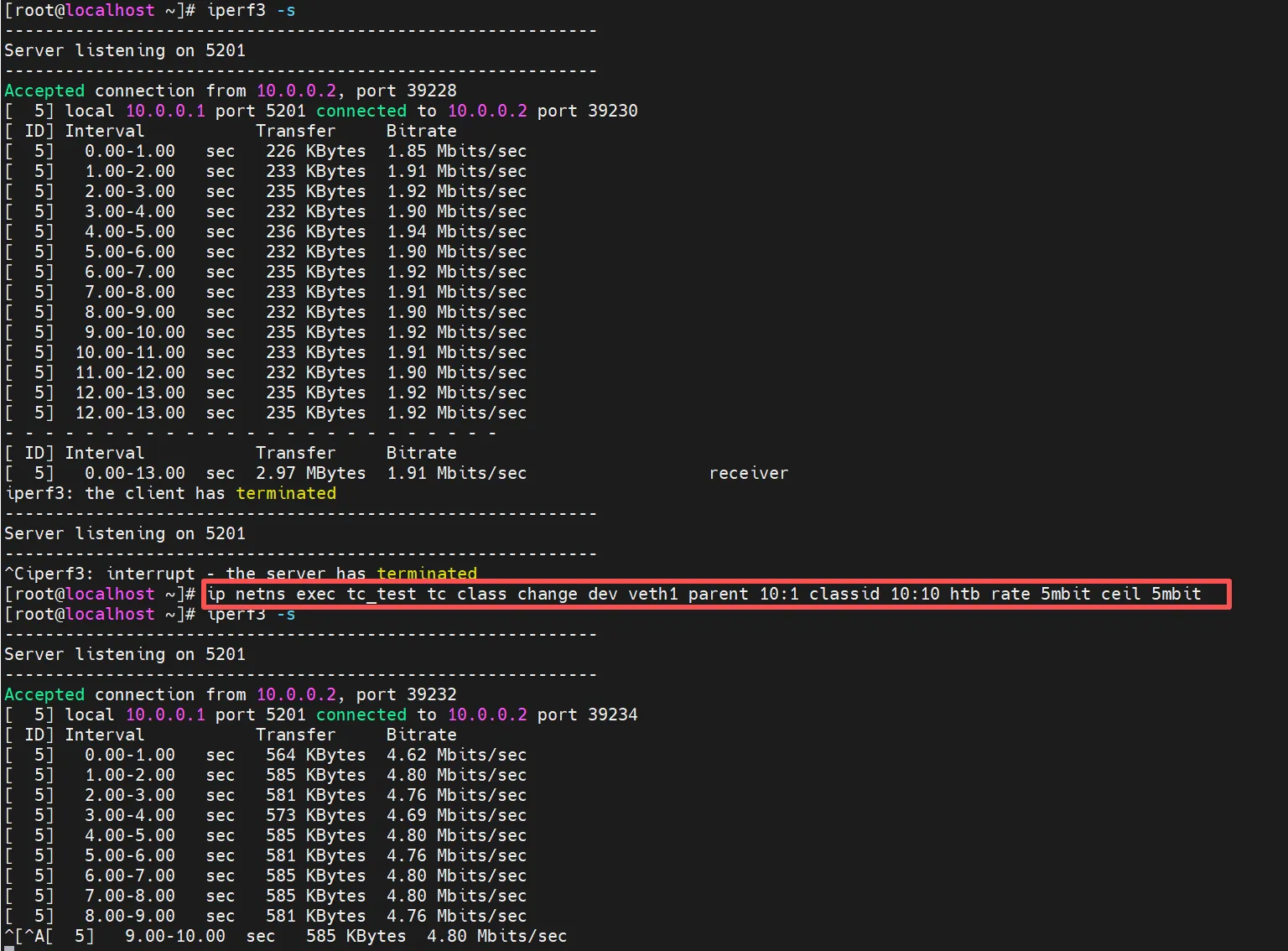
# 每天凌晨 00:00 触发:限速 # 将 10:10 队列的阈值调整为基础 1M,最高弹性借用到 2M 0 0 * * * /usr/sbin/ip netns exec tc_test /usr/sbin/tc class change dev veth1 parent 10:1 classid 10:10 htb rate 1mbit ceil 2mbit # 每天傍晚 18:00 触发:解除限速 # 将 10:10 队列的阈值直接拉满,与其父类classid 10:1的5M一样 0 18 * * * /usr/sbin/ip netns exec tc_test /usr/sbin/tc class change dev veth1 parent 10:1 classid 10:10 htb rate 5mbit ceil 5mbit
这里直接执行测试了,执行change后继续打流,发现放开了
0 18 * * * /usr/sbin/ip netns exec tc_test /usr/sbin/tc class change dev veth1 parent 10:1 classid 10:10 htb rate 5mbit ceil 5mbit
还有一种就是通过iptables的mangle表使用time模块、mark标记来实现,但是这里没实验成功,听ai讲是
基于 CentOS 8 / RHEL 8 的现代操作系统由于底层切换至 nf_tables,官方已将 xt_time 内核模块移除,导致规则无法下发。
ip netns exec tc_test iptables -t mangle -A POSTROUTING -o veth1 -m time –timestart 00:00 –timestop 18:00 –kerneltz -j MARK –set-mark 10
备注:
其实htb只是属于一个模块,内核模块 sch_htb,并不是所有硬件都会支持,比如碰见rk3528等类型,会提示Error: Specified qdisc kind is unknown.模块不支持!
可以用添加qdisc规则命令检测是否支持:
tc qdisc add dev eth0 root handle 314: htb default 1

© 版权声明
文章版权归作者所有,未经允许请勿转载。


